Michel Bellanger (Directeur Marketing, Carrefour Media) et Philippe Périé (Vice-Président Data & Algorithmes, Ogury) étaient les invités du petit déjeuner IREP que nous avons eu le plaisir d’animer le 28 février.
Ci-après le compte-rendu complet de ce petit déjeuner.
-
Carrefour Media et Ogury en tant que sociétés
–Ogury a été créée en septembre 2014, et est composée de 150 personnes, à ce jour (droit anglais mais siège à Paris). Le CA 2017 est d’un peu plus de 40 millions d’euros. Cette société est, historiquement, une société de technologie dédiée au ciblage publicitaire, au branding et à la performance sur mobile (Android uniquement pour l’instant). Mais le modèle évolue du fait de la croissance et de la granularité des données. Ogury se définit maintenant comme une « mobile data company » pour offrir des outils de monétisation, de ciblages publicitaires et d’analyses pour les annonceurs et les éditeurs.
–Carrefour Media est le quatrième contributeur à la marge de Carrefour France et emploie 40 personnes. Ses clients sont les marques référencées chez Carrefour principalement. Les performances de la régie et ses actions autour de la data font que la nouvelle gouvernance de l’entreprise réinvestit énormément le sujet et les moyens afférents.
-
Comment faites-vous pour suivre les individus ou consommateurs?
- Le terme suivre est rejeté par les 2 participants.
Pour Philippe Périé (Ogury), on n’est pas dans une logique de suivre les individus de façon individuelle et en permanence, cela ferait beaucoup trop de données ! Cependant, la valorisation des données est faite, à la demande, dans des contextes particuliers pour des clients éditeurs, annonceurs ou entreprises. La donnée est agrégée, anonyme pour créer des cibles, des profils et pour décrire des audiences, et non pas pour suivre un individu.
Michel Bellanger (Carrefour Media) met lui aussi en avant la connaissance client pour répondre à des attentes et non pas suivre une personne.
Ogury s’associe à des milliers d’applications, dans le monde entier, pour générer des données d’intérêt et de comportement uniques directement à partir de plus de 400 millions de profils d’utilisateurs mobiles uniques (250 millions avec opt-in) dans plus de 120 pays.
L’éditeur fait rentrer, dans son application, le SDK Ogury qui va, à partir de l’opt-in, collecter des données brutes (bas niveau) traduites en données significatives et utiles (applications installées, applications utilisées, connectivité et sites visités…) grâce à une technologie propriétaire. Cette vue, first party, est complète, assez unique en profondeur, en récurrence, en précision, et disponible nulle part ailleurs. La récolte des données brutes est importante pour minimiser l’empreinte du SDK sur la batterie du smartphone, un des plus d’Ogury.
Ces informations sont, ensuite, transformées par des équipes de data scientists en visites, en fréquentation, en durée. Au final, ces données sont enrichies dans une optique de ciblage publicitaire mais sont proposées aussi comme vecteur de connaissance pour un éditeur : le parcours de l’utilisateur de son application était celui-là il y a une semaine, et a été celui-ci 2 semaines après… Originellement, Ogury s’est lancé en payant un CPM assez généreux (entre 8 et 12 €), cette proposition attractive n’était pas la seule du marché, les éditeurs ont alors souhaité disposer de plus de connaissance. Ogury va aussi vers un modèle NO PUB pour proposer de la connaissance d’audiences aux clients.
Pour répondre aux enjeux de revenus de Carrefour, l’enseigne a développé des outils permettant de répondre aux attentes des consommateurs : une offre, un service omnicanal, plus de générosité, plus de personnalisation.
Carrefour a 3 grands types de connaissance clients.
- Les transactions collectées via les tickets de caisse (anonyme) et via la carte fidélité personnelle (14,3 millions de porteurs, 27 mois d’historique d’achat à l’EAN, au code-barre). Les premières sont de l’informatique, les secondes sont de l’intelligence. Avec les encartés, Carrefour retrace 85% du CA des hypermarchés, mais moins dans les magasins de proximité.
- La navigation / fréquentation média: magasins on (adserver / tracking) et off (carte fidélité). Les outils qui, il y a 5 ans, étaient managés par les agences (ex ad serveur) ont été réinternalisés au principe que c’était de la connaissance client qui permet de personnaliser la relation avec l’individu. La clé du commerce pour Carrefour étant la personnalisation, l’internalisation des outils était indispensable. Un questionnaire média est aussi adressé à certains porteurs de carte.
- Les données externes de type Météo, de la donnée de contexte.
-
Pour quelle(s) finalité(s) ?
« Après la connaissance, l’insight, il y a la dynamique de la connaissance »
Michel Bellanger, Carrefour Media
« On dépasse le simple taux de clic en remettant dans le contexte de l’activité via le mobile. »
Philippe Périé, Ogury
Pour Carrefour Media, les objectifs sont, par nature, pour des clients/fabricants de marques alimentaires avec la volonté de construire de nouvelles coopérations avec les marques.
Ces nouvelles coopérations doivent être :
- Durables, elles doivent donc répondre aux enjeux de transparence qu’attendent les annonceurs pour installer la confiance
- Massives donc industrialisées, il faut créer de nouveaux outils avec ceux qui existent
- ROIste, c’est le consommateur final qui valide les opérations en changeant son comportement, l’efficacité est un bon indicateur de cette acceptation. Les outils de mesure, BI, doivent être co- construits et partagés.
On explique alors aux annonceurs les opportunités ou menaces de leur business par rapport à la catégorie, la famille de produit, la promotion, la météo. Au-delà de la mesure de la performance, c’est la compréhension de cette performance qui est faite.
Evidemment, tout cela à un coût et une valeur. Que ce soit pour les annonceurs, leurs agences ou les éditeurs, Carrefour dispose, maintenant, d’outils pour répondre à leurs besoins. Les experts qui analysent, ne sont pas forcément en interne chez Carrefour, l’objectif est de connecter la donnée avec des partenaires (5 équipes différentes dans 4 entreprises différentes).
Mais après la connaissance, l’insight, il y a la dynamique de la connaissance. Associé à un CA, il y a une liste de contacts qui peut être activée pour changer les comportements : comment activer un segment d’audience sur un comportement d’achat via des médias, des services existants, des services à inventer (livraison de bouteilles pour de gros consommateurs de boisson gazeuse, pressing gratuit pour x chemises pour un lessivier…). L’important étant de créer une relation.
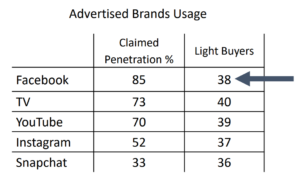
Chez Ogury, en termes d’organisation, le traitement de la donnée est internalisé, une équipe « data rafinery » existe même pour préparer les données. Mais sur le fond de l’utilisation des données, au-delà de la monétisation en CPM ou de l’engagement en performances de « delivery », l’apport de connaissance majeur aux éditeurs et annonceurs se fait par la compréhension du comportement de leurs cibles en dehors de l’univers qu’ils contrôlent avec leurs applications : mixités, cross usage, exclusivité, profils… sur de longues séries.
On retrouve aussi une notion dynamique du coté publicitaire en apportant de la pertinence et de la parcimonie dans la communication. Les individus sont éduqués, sont conscients de la collecte de données par les applications et les terminaux et attendent en retour des interactions proactives et contextualisées. De nombreuses études le montrent. La mission est aussi de permettre un meilleur dialogue entre annonceurs, entreprises et consommateurs.
Des progiciels édités par Ogury pour ses besoins d’analyse de la donnée en interne, sont aussi dans les mains des clients pour apporter une connaissance plus profonde de ce qui a fonctionné ou non dans une campagne, dans un segment visé, en dépassant le simple taux de clic mais en remettant dans le contexte de l’activité via le mobile.
-
Le « sans couture » (seamless), une réalité ?
« A notre expérience sur les marques alimentaires, le sans couture n’existe pas ! »
Michel Bellanger, Carrefour Media
Carrefour travaille avec les wallgarden « Google, Facebook, Apple… » mais les premiers jardins clos ce sont les magasins ! Ils se sont digitalisés, ils ont monté chacun leur écosystème.
Si on se réfère au Lumascape, tous ces acteurs de ce monde-là ne donnent pas l’impression de communiquer les uns avec les autres, chacun a son propre langage, sa propre technologie et produit énormément pour alimenter les directions marketing. Ainsi, un directeur marketing a toutes ces solutions face à lui et a l’impression d’obtenir une vraie victoire quand il réussit à connecter tel système avec sa DMP. Le problème c’est que le système Facebook ou autre ne communique pas avec x ou avec y… Avoir le parcours complet du client d’un magasin est ambitieux car cela signifie, d’une part, que l’on a la transparence totale sur le marché, ce qui n’est pas le cas, et d’autre part que l’on ait de la réconciliation à l’individu (pas au device) ce qui n’est pas le cas non plus !
Chacun des éditeurs, des partenaires, impose une règle avec le risque de sacrées surprises.
Mesurer est un risque car cela peut conduire à annoncer que ce n’est pas efficace mais cela recèle des opportunités car on peut imaginer améliorer les choses. Toutefois, la chaîne et le parcours risquent de bouger et la position qu’on a dans la chaîne peut évoluer.
Carrefour est en train d’organiser un « hôtel » dans lequel il n’y a qu’un seul langage commun, le client final (réconcilier la donnée à l’individu), et chacun des partenaires (les 450 plateformes marketing) peut réserver une chambre qui dispose d’une porte sur toutes les autres chambres en maitrisant la sécurité de la donnée et les règles de privacy. Cet hôtel, est pour l’instant plus un Airbnb (on fait à la main) mais a vocation à devenir l’hôtel décrit, c’est-à-dire, l’industrialisation des réconciliations. Cela fonctionne remarquablement bien.
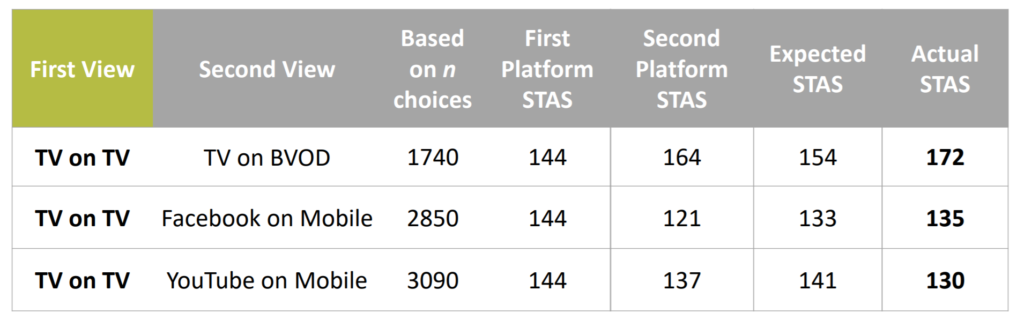
L’an dernier, la régie a fait une communication sur le VOPO (View On Line Purchase Off Line), le (ROPO n’existe pas en alimentaire), la réconciliation entre les données transactionnelles et les données d’exposition on line.
On travaille déjà avec Facebook et on mesure l’efficacité du digital Facebook sur l’achat chez Carrefour. Avec Google ou Appnexus, on reconcilie à l’individu les impressions digitales avec un ticket de caisse, ce qui permet de mesurer un effet (tant de chiffre incrémental, tant de recrutement incremental…) et de produire des courbes de réponse d’effet sur les ventes. Les annonceurs optimisent leurs campagnes sur des cookies mais quand on se place à l’individu, on constate qu’il a 2.5 cookies. Donc optimiser au cookie c’est voir double. Optimiser en temps réel le lundi, par exemple, quand les achats se font le jeudi, ça ne sert pas à grand-chose. Enfin, une campagne, en soi, a peu d’effet, c’est la répétition des campagnes qui fait la construction du ROI. La donnée Carrefour se teste sur 6 mois, pas en une vague, pour accumuler suffisamment de pression commerciale en digital pour obtenir un résultat.
Ogury travaille sur des données Android qui est un écosystème très fragmenté avec de nombreux constructeurs, de nombreuses versions qui ne travaillent pas toutes de la même façon.
Cela arrive qu’il y ait des trous dans les données qu’il faut détecter mais globalement l’ensemble est assez propre. Les biais qui existent sont techniques. Pas de biais non plus de cookie car l’information est à l’Android ID du smartphone qui est un objet personnel tant que l’on ne change pas de device, qu’on ne remette pas à zéro l’Android ID (c’est possible) ou tant que vous ne démissionnez pas d’Ogury !
-
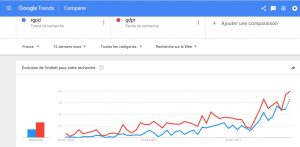
RGPD ? Privacy ? Un frein ? opportunité ?
« Le RGPD va vraiment faire le tri entre le bon grain et l’ivraie ».
Philippe Périé, Ogury
« Il y aura des procès, dès 2018, car il y a une vraie volonté politique »
Michel Bellanger, Carrrefour Media
Pour Ogury, l’arrivée du RGPD est une situation vécue sereinement car dès les débuts de la société, être avec un opt-in explicite était la règle. Nous avons toujours préféré perdre de la donnée que d’en collecter de manière non transparente.
C’est une opportunité attendue avec impatience car :
- cela va provoquer un assainissement du marché de ceux qui ne sont pas vertueux et aussi mettre en avant l’unicité, la granularité de nos données
- et c’est un bénéfice pour l’utilisateur aussi, car il aura moins de publicité mais elle sera plus intéressante, car plus ciblée et plus contextualisée. L’acceptation publicitaire sera plus forte.
Le RGPD est aussi une opportunité pour Carrefour. Le même argument de nettoyage du marché est aussi mis en avant. Des cookies distributeurs circulent sur le marché, d’où sortent-ils ? Du probabilisé plus que du réel !
Soyons audacieux et saisissons le RGPD pour positionner Carrefour pas seulement sur une carte de fidélité, pourquoi ne pas proposer aux clients de les rémunérer pour l’usage de leurs données en euros sur leur carte fidélité ? Pourquoi pas un pass data ou le client peut gérer ces opt-in opt-out pour tout ? Il y a une vraie réflexion autour d’une offre de services et pas seulement l’offre de produit. La force de Google et Facebook ? Un service de qualité. Le RGPD constitue une vraie opportunité pour les Directeurs marketing d’apporter un vrai service.
- A-t-on encore besoin du parcours des pensées ? Les sociétés d’études servent à quelque chose ?
« S’il y a biais ou censure et pas d’élément pour contextualiser, caler ou cadrer, les masses de données ne vont pas apporter grand-chose, au contraire on est sûr de raconter n’importe quoi »
Philippe Périé, Ogury
Après 15 ans à TNS et IPSOS, Philippe Périé ne peut fournir une réponse objective ! Pour lui, on ne répond pas aux mêmes objectifs.
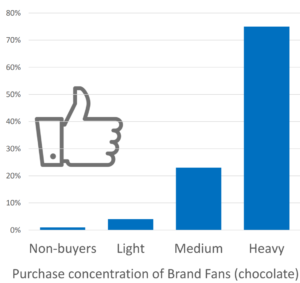
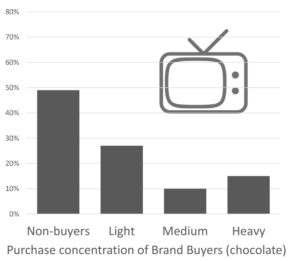
L’étude permet d’avoir accès à de la donnée couvrant tout le marché, les occasions (pas seulement l’interaction que le client a avec les points de contacts contrôlés par l’entreprise). S’il y a biais ou censure et pas d’élément pour contextualiser, caler ou cadrer, les masses de données ne vont pas apporter grand-chose, au contraire on est sûr de raconter n’importe quoi ! La donnée étude (quali/quanti) permet cette mise en perspective.
La récolte passive et massive de données apporte des informations de comportements et d’usages contextualisées, sur de longues périodes et sur de tels volumes et degrés de granularité que l’on peut descendre à des niveaux de résolutions inaccessibles autrement, et sans biais de souvenir.
En résumé, l’étude permet la mise en perspective, la couverture hors du champ de ce qui est pris par nos canaux, on est plus sur des problématiques de compréhension de marché, consommateur… Les données massives apportent la granularité, longues séries, exhaustivité, données contextuelles. On est alors plus souvent sur de l’opérationnel.
Ensuite, il y a tous les modèles d’hybridation possibles.
Selon Carrefour, la base de données permet d’optimiser mais, le plus important, c’est innover, avoir des idées. Ce sont souvent les clients qui en parlent le mieux et ce n’est pas dans les bases de données qu’on les trouve.










){kind=link}
 (compte rendu partial et partiel conférence SNPTV)){kind=link}
{kind=link}
){kind=link}
, le parcours du consommateur ON et OFF (Carrefour Media) (compte rendu impartial et complet)){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
){kind=link}