
Pendant des lustres, les chercheurs en organisation ont fait l’hypothèse que la performance d’une entreprise dépendait de la structure formelle de cette entreprise mais aussi de la façon dont l’information circulait.
Jusqu’à présent, le flux d’information n’était pas une chose aisée à mesurer. Avec le digital, la donnée est là et a permis à Duncan Watts et son équipe de tester l’hypothèse précédente (Duncan Watts, le génial chercheur qui a validé, à l’ère digitale, le principe du « monde est petit », fait partie depuis quelques années, des équipes de recherche de Microsoft)
De quelles données parle-t-on ?
Celles des mails, pas le contenu mais les meta données de chaque mail (si vous êtes sur gmail, prenez un de vos mails, cliquez sur la flèche à droite et faites « afficher l’original », vous verrez. Ça doit être du même genre sur Outlook de Microsoft) ainsi que des informations plus classiques comme le titre du salarié, sa localisation, et les réponses à une enquête (satisfaction des employés vs leur manager). Tout ceci aux USA, sur des données de 2015, avec toutes les garanties de préservation de la vie privée de la terre !
Quel but ?
Avec des données de mail, peut-on prédire :
- Le niveau de confiance des employés dans l’efficacité de leur manager
- Le fait que différents groupes dans l’entreprise collaborent efficacement
- La satisfaction des employés quant à l’équilibre vie au travail et vie privée
Comment ?
Là, ils se sont amusés (moi j’aime !) à procéder à 3 types d’analyse :
- Du très classique en analyse de données, une analyse logistique
- Du machine learning (algorithme random forest) SANS les meta données mail
- Du machine learning (algorithme random forest) AVEC les meta données mail
Résultats ?
Ils ne se sont intéressés qu’au 15% d’individus insatisfaits.
| Questions posées | Modèle logistique | Random Forest SANS les données mail | Random Forest AVEC les données mail | Caractéristique du mail la plus prédictive |
| Satisfaction vs son propre manager | 20% | 69% | 93% | Délai de réponse du manager (le pire, un long délai) |
| Collaboration dans l’entreprise | 27% | 70% | 89% | Taille du mail de réponse du manager (le pire, une réponse courte) |
| Equilibre vie au travail/vie privée | 18% | 42% | 80% | % de mails envoyés en dehors des heures de bureaux (plus il y en a, plus c’est mauvais) |
D’un point de vue analyse de données, le modèle « random forest AVEC données des mails » est supérieur aux autres solutions.
Sur le fond (colonne de droite), a priori rien de renversant, les résultats sont frappés au coin du bon sens et vous vous dites « tout ça pour ça ! ».
En y regardant à 2 fois, on peut aller plus loin. En prenant, par exemple, l’équilibre privée/travail, si le nombre de mails en dehors des heures travaillées est un facteur important, on aurait pu s’attendre à ce que le volume global de mails reçus ou envoyés ou sa distribution selon les jours aient aussi un effet. NON !
Alors ?
En ressources humaines, comme dans bien des domaines, on pourrait piloter plus facilement la satisfaction des employés en utilisant les données qui existent en flux continu. Avec un grand bémol, NE PAS FLIQUER !!
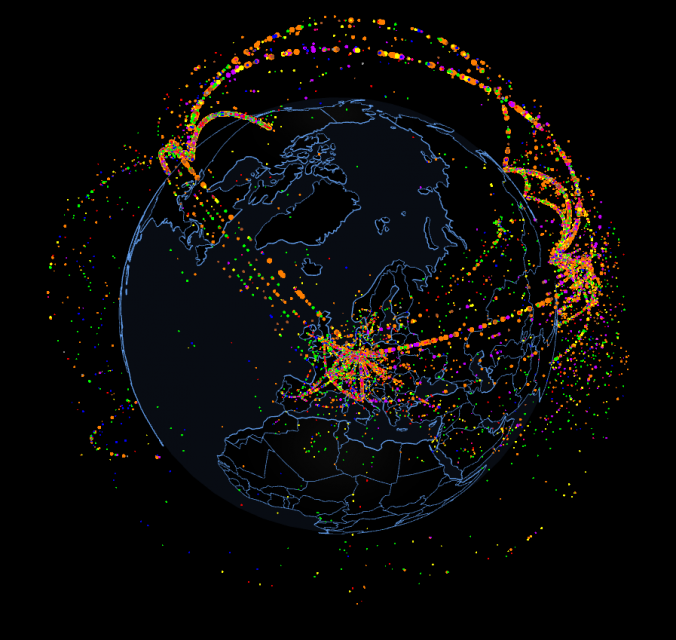
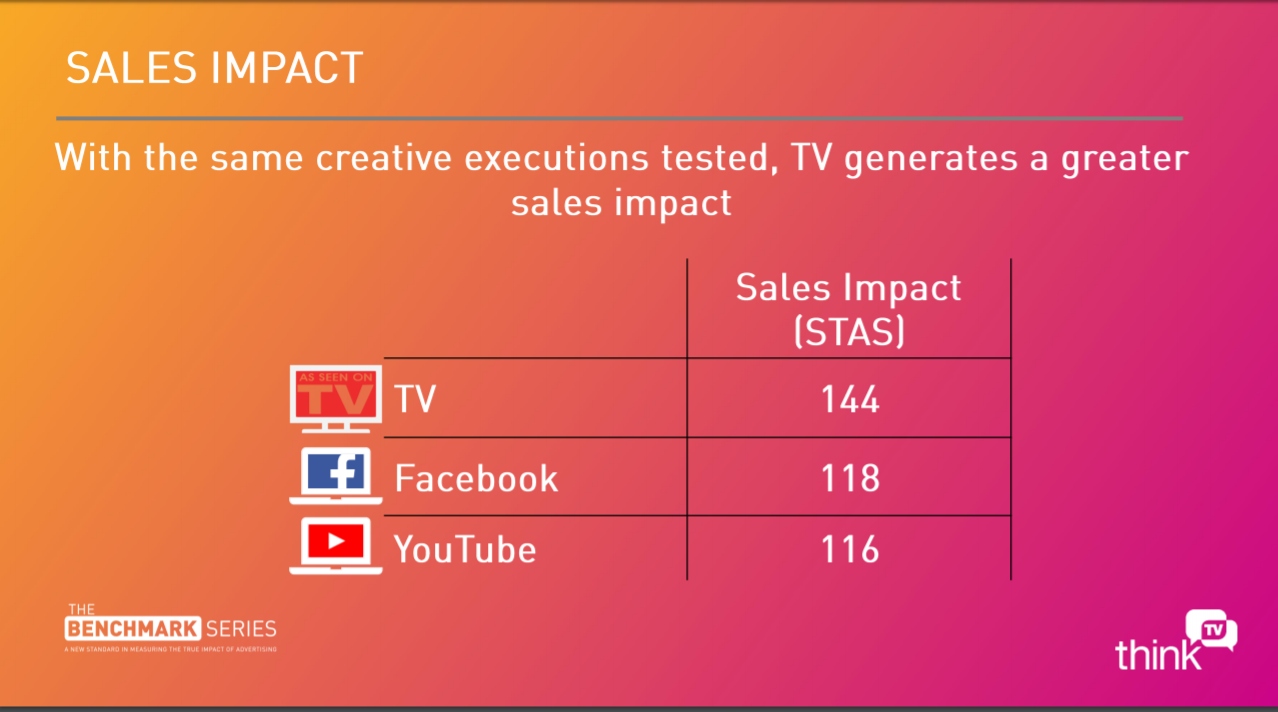
Au fait, l’image c’est le réseau des employés Microsoft en fonction des échanges mails.
L’article originel (en anglais)
https://medium.com/@duncanjwatts/the-organizational-spectroscope-7f9f239a897c











{kind=link}
{kind=link}
){kind=link}
 2/2){kind=link}
){kind=link}
){kind=link}
{kind=link}
{kind=link}
{kind=link}