
Les articles les plus lus en 2018 sur ce blog: une tribune et 4 comptes-rendus de conférence.
Merci de nous lire!
Merci de nous lire!
Ci-après le compte-rendu complet de ce petit déjeuner.
–Ogury a été créée en septembre 2014, et est composée de 150 personnes, à ce jour (droit anglais mais siège à Paris). Le CA 2017 est d’un peu plus de 40 millions d’euros. Cette société est, historiquement, une société de technologie dédiée au ciblage publicitaire, au branding et à la performance sur mobile (Android uniquement pour l’instant). Mais le modèle évolue du fait de la croissance et de la granularité des données. Ogury se définit maintenant comme une « mobile data company » pour offrir des outils de monétisation, de ciblages publicitaires et d’analyses pour les annonceurs et les éditeurs.
–Carrefour Media est le quatrième contributeur à la marge de Carrefour France et emploie 40 personnes. Ses clients sont les marques référencées chez Carrefour principalement. Les performances de la régie et ses actions autour de la data font que la nouvelle gouvernance de l’entreprise réinvestit énormément le sujet et les moyens afférents.
Pour Philippe Périé (Ogury), on n’est pas dans une logique de suivre les individus de façon individuelle et en permanence, cela ferait beaucoup trop de données ! Cependant, la valorisation des données est faite, à la demande, dans des contextes particuliers pour des clients éditeurs, annonceurs ou entreprises. La donnée est agrégée, anonyme pour créer des cibles, des profils et pour décrire des audiences, et non pas pour suivre un individu.
Michel Bellanger (Carrefour Media) met lui aussi en avant la connaissance client pour répondre à des attentes et non pas suivre une personne.
Ogury s’associe à des milliers d’applications, dans le monde entier, pour générer des données d’intérêt et de comportement uniques directement à partir de plus de 400 millions de profils d’utilisateurs mobiles uniques (250 millions avec opt-in) dans plus de 120 pays.
L’éditeur fait rentrer, dans son application, le SDK Ogury qui va, à partir de l’opt-in, collecter des données brutes (bas niveau) traduites en données significatives et utiles (applications installées, applications utilisées, connectivité et sites visités…) grâce à une technologie propriétaire. Cette vue, first party, est complète, assez unique en profondeur, en récurrence, en précision, et disponible nulle part ailleurs. La récolte des données brutes est importante pour minimiser l’empreinte du SDK sur la batterie du smartphone, un des plus d’Ogury.
Ces informations sont, ensuite, transformées par des équipes de data scientists en visites, en fréquentation, en durée. Au final, ces données sont enrichies dans une optique de ciblage publicitaire mais sont proposées aussi comme vecteur de connaissance pour un éditeur : le parcours de l’utilisateur de son application était celui-là il y a une semaine, et a été celui-ci 2 semaines après… Originellement, Ogury s’est lancé en payant un CPM assez généreux (entre 8 et 12 €), cette proposition attractive n’était pas la seule du marché, les éditeurs ont alors souhaité disposer de plus de connaissance. Ogury va aussi vers un modèle NO PUB pour proposer de la connaissance d’audiences aux clients.
Pour répondre aux enjeux de revenus de Carrefour, l’enseigne a développé des outils permettant de répondre aux attentes des consommateurs : une offre, un service omnicanal, plus de générosité, plus de personnalisation.
Carrefour a 3 grands types de connaissance clients.
« Après la connaissance, l’insight, il y a la dynamique de la connaissance »
Michel Bellanger, Carrefour Media
« On dépasse le simple taux de clic en remettant dans le contexte de l’activité via le mobile. »
Philippe Périé, Ogury
Pour Carrefour Media, les objectifs sont, par nature, pour des clients/fabricants de marques alimentaires avec la volonté de construire de nouvelles coopérations avec les marques.
Ces nouvelles coopérations doivent être :
On explique alors aux annonceurs les opportunités ou menaces de leur business par rapport à la catégorie, la famille de produit, la promotion, la météo. Au-delà de la mesure de la performance, c’est la compréhension de cette performance qui est faite.
Evidemment, tout cela à un coût et une valeur. Que ce soit pour les annonceurs, leurs agences ou les éditeurs, Carrefour dispose, maintenant, d’outils pour répondre à leurs besoins. Les experts qui analysent, ne sont pas forcément en interne chez Carrefour, l’objectif est de connecter la donnée avec des partenaires (5 équipes différentes dans 4 entreprises différentes).
Mais après la connaissance, l’insight, il y a la dynamique de la connaissance. Associé à un CA, il y a une liste de contacts qui peut être activée pour changer les comportements : comment activer un segment d’audience sur un comportement d’achat via des médias, des services existants, des services à inventer (livraison de bouteilles pour de gros consommateurs de boisson gazeuse, pressing gratuit pour x chemises pour un lessivier…). L’important étant de créer une relation.
Chez Ogury, en termes d’organisation, le traitement de la donnée est internalisé, une équipe « data rafinery » existe même pour préparer les données. Mais sur le fond de l’utilisation des données, au-delà de la monétisation en CPM ou de l’engagement en performances de « delivery », l’apport de connaissance majeur aux éditeurs et annonceurs se fait par la compréhension du comportement de leurs cibles en dehors de l’univers qu’ils contrôlent avec leurs applications : mixités, cross usage, exclusivité, profils… sur de longues séries.
On retrouve aussi une notion dynamique du coté publicitaire en apportant de la pertinence et de la parcimonie dans la communication. Les individus sont éduqués, sont conscients de la collecte de données par les applications et les terminaux et attendent en retour des interactions proactives et contextualisées. De nombreuses études le montrent. La mission est aussi de permettre un meilleur dialogue entre annonceurs, entreprises et consommateurs.
Des progiciels édités par Ogury pour ses besoins d’analyse de la donnée en interne, sont aussi dans les mains des clients pour apporter une connaissance plus profonde de ce qui a fonctionné ou non dans une campagne, dans un segment visé, en dépassant le simple taux de clic mais en remettant dans le contexte de l’activité via le mobile.
« A notre expérience sur les marques alimentaires, le sans couture n’existe pas ! »
Michel Bellanger, Carrefour Media
Carrefour travaille avec les wallgarden « Google, Facebook, Apple… » mais les premiers jardins clos ce sont les magasins ! Ils se sont digitalisés, ils ont monté chacun leur écosystème.
Si on se réfère au Lumascape, tous ces acteurs de ce monde-là ne donnent pas l’impression de communiquer les uns avec les autres, chacun a son propre langage, sa propre technologie et produit énormément pour alimenter les directions marketing. Ainsi, un directeur marketing a toutes ces solutions face à lui et a l’impression d’obtenir une vraie victoire quand il réussit à connecter tel système avec sa DMP. Le problème c’est que le système Facebook ou autre ne communique pas avec x ou avec y… Avoir le parcours complet du client d’un magasin est ambitieux car cela signifie, d’une part, que l’on a la transparence totale sur le marché, ce qui n’est pas le cas, et d’autre part que l’on ait de la réconciliation à l’individu (pas au device) ce qui n’est pas le cas non plus !
Chacun des éditeurs, des partenaires, impose une règle avec le risque de sacrées surprises.
Mesurer est un risque car cela peut conduire à annoncer que ce n’est pas efficace mais cela recèle des opportunités car on peut imaginer améliorer les choses. Toutefois, la chaîne et le parcours risquent de bouger et la position qu’on a dans la chaîne peut évoluer.
Carrefour est en train d’organiser un « hôtel » dans lequel il n’y a qu’un seul langage commun, le client final (réconcilier la donnée à l’individu), et chacun des partenaires (les 450 plateformes marketing) peut réserver une chambre qui dispose d’une porte sur toutes les autres chambres en maitrisant la sécurité de la donnée et les règles de privacy. Cet hôtel, est pour l’instant plus un Airbnb (on fait à la main) mais a vocation à devenir l’hôtel décrit, c’est-à-dire, l’industrialisation des réconciliations. Cela fonctionne remarquablement bien.
L’an dernier, la régie a fait une communication sur le VOPO (View On Line Purchase Off Line), le (ROPO n’existe pas en alimentaire), la réconciliation entre les données transactionnelles et les données d’exposition on line.
On travaille déjà avec Facebook et on mesure l’efficacité du digital Facebook sur l’achat chez Carrefour. Avec Google ou Appnexus, on reconcilie à l’individu les impressions digitales avec un ticket de caisse, ce qui permet de mesurer un effet (tant de chiffre incrémental, tant de recrutement incremental…) et de produire des courbes de réponse d’effet sur les ventes. Les annonceurs optimisent leurs campagnes sur des cookies mais quand on se place à l’individu, on constate qu’il a 2.5 cookies. Donc optimiser au cookie c’est voir double. Optimiser en temps réel le lundi, par exemple, quand les achats se font le jeudi, ça ne sert pas à grand-chose. Enfin, une campagne, en soi, a peu d’effet, c’est la répétition des campagnes qui fait la construction du ROI. La donnée Carrefour se teste sur 6 mois, pas en une vague, pour accumuler suffisamment de pression commerciale en digital pour obtenir un résultat.
Ogury travaille sur des données Android qui est un écosystème très fragmenté avec de nombreux constructeurs, de nombreuses versions qui ne travaillent pas toutes de la même façon.
Cela arrive qu’il y ait des trous dans les données qu’il faut détecter mais globalement l’ensemble est assez propre. Les biais qui existent sont techniques. Pas de biais non plus de cookie car l’information est à l’Android ID du smartphone qui est un objet personnel tant que l’on ne change pas de device, qu’on ne remette pas à zéro l’Android ID (c’est possible) ou tant que vous ne démissionnez pas d’Ogury !
« Le RGPD va vraiment faire le tri entre le bon grain et l’ivraie ».
Philippe Périé, Ogury
« Il y aura des procès, dès 2018, car il y a une vraie volonté politique »
Michel Bellanger, Carrrefour Media
Pour Ogury, l’arrivée du RGPD est une situation vécue sereinement car dès les débuts de la société, être avec un opt-in explicite était la règle. Nous avons toujours préféré perdre de la donnée que d’en collecter de manière non transparente.
C’est une opportunité attendue avec impatience car :
Le RGPD est aussi une opportunité pour Carrefour. Le même argument de nettoyage du marché est aussi mis en avant. Des cookies distributeurs circulent sur le marché, d’où sortent-ils ? Du probabilisé plus que du réel !
Soyons audacieux et saisissons le RGPD pour positionner Carrefour pas seulement sur une carte de fidélité, pourquoi ne pas proposer aux clients de les rémunérer pour l’usage de leurs données en euros sur leur carte fidélité ? Pourquoi pas un pass data ou le client peut gérer ces opt-in opt-out pour tout ? Il y a une vraie réflexion autour d’une offre de services et pas seulement l’offre de produit. La force de Google et Facebook ? Un service de qualité. Le RGPD constitue une vraie opportunité pour les Directeurs marketing d’apporter un vrai service.
« S’il y a biais ou censure et pas d’élément pour contextualiser, caler ou cadrer, les masses de données ne vont pas apporter grand-chose, au contraire on est sûr de raconter n’importe quoi »
Philippe Périé, Ogury
Après 15 ans à TNS et IPSOS, Philippe Périé ne peut fournir une réponse objective ! Pour lui, on ne répond pas aux mêmes objectifs.
L’étude permet d’avoir accès à de la donnée couvrant tout le marché, les occasions (pas seulement l’interaction que le client a avec les points de contacts contrôlés par l’entreprise). S’il y a biais ou censure et pas d’élément pour contextualiser, caler ou cadrer, les masses de données ne vont pas apporter grand-chose, au contraire on est sûr de raconter n’importe quoi ! La donnée étude (quali/quanti) permet cette mise en perspective.
La récolte passive et massive de données apporte des informations de comportements et d’usages contextualisées, sur de longues périodes et sur de tels volumes et degrés de granularité que l’on peut descendre à des niveaux de résolutions inaccessibles autrement, et sans biais de souvenir.
En résumé, l’étude permet la mise en perspective, la couverture hors du champ de ce qui est pris par nos canaux, on est plus sur des problématiques de compréhension de marché, consommateur… Les données massives apportent la granularité, longues séries, exhaustivité, données contextuelles. On est alors plus souvent sur de l’opérationnel.
Ensuite, il y a tous les modèles d’hybridation possibles.
Selon Carrefour, la base de données permet d’optimiser mais, le plus important, c’est innover, avoir des idées. Ce sont souvent les clients qui en parlent le mieux et ce n’est pas dans les bases de données qu’on les trouve.
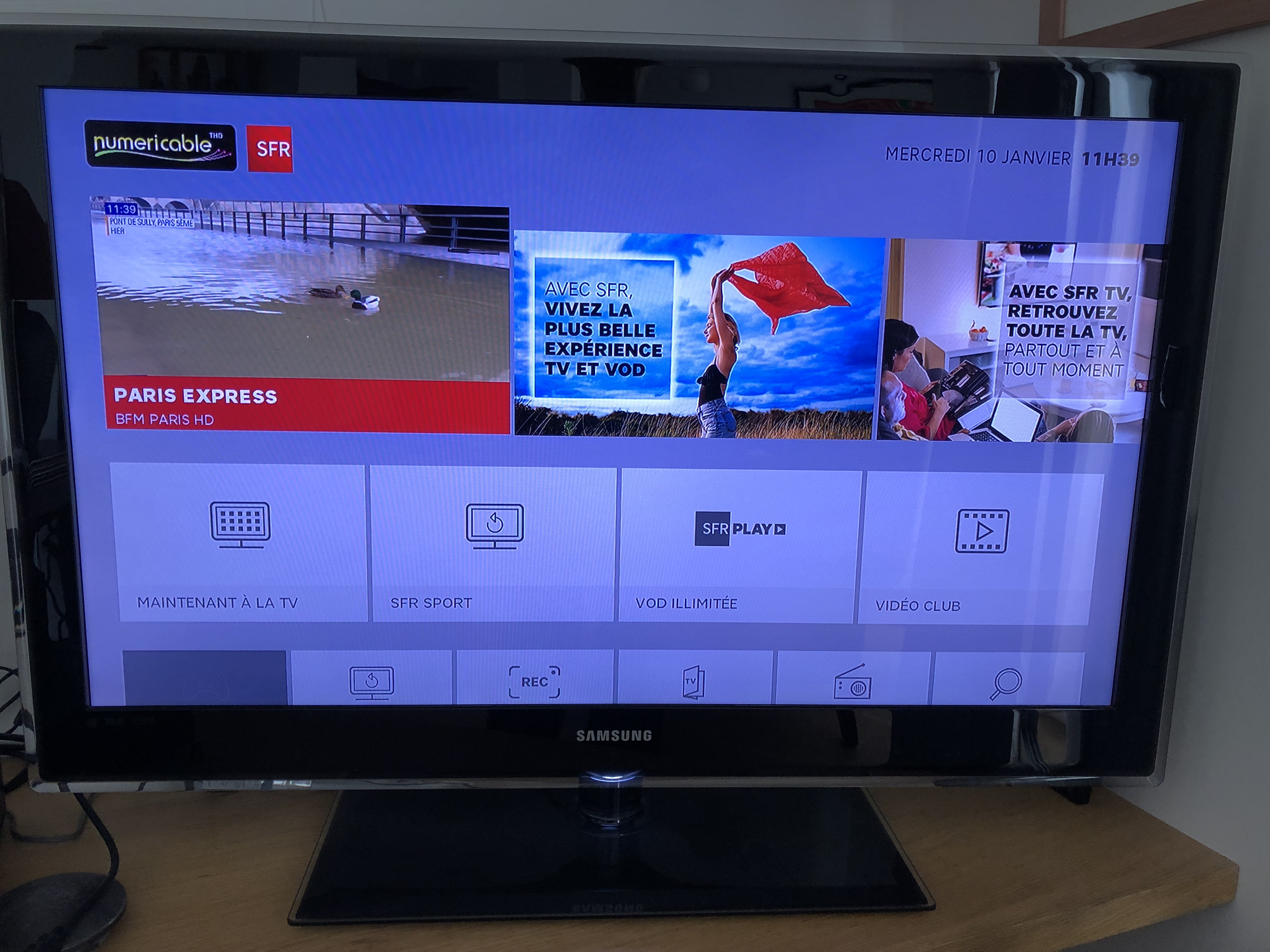
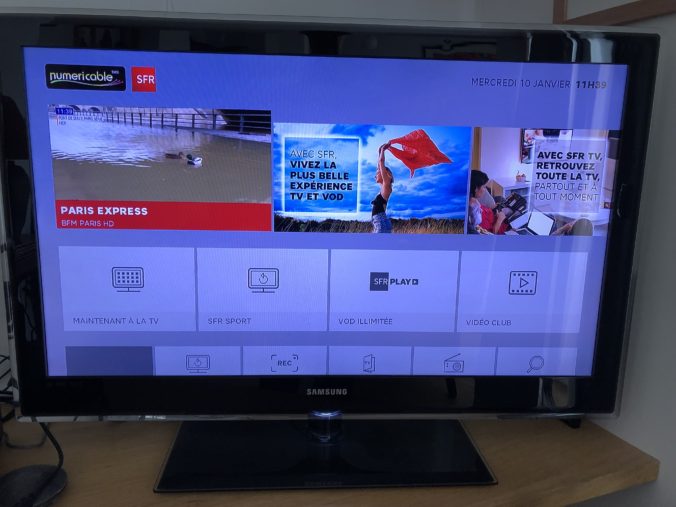
Pour mémoire, BFM Paris fait partie des chaines du groupe ALTICE/SFR et Paris est le point de force du réseau Numéricable en termes d’implantation.
INous ne pensons pas nous tromper, les règles de comptabilisation n’ont pas changé fondamentalement, ces quelques instants d’activité du son et de l’image de BFM Paris sont identifiés, répertoriés dans les audimètres des panélistes du Mediamat de Mediametrie (la chaîne est marquée, taggée).
Ainsi, lors du traitement de l’audience chez Mediametrie, ces quelques instants sont pris en compte et permettent à la chaîne BFM Paris d’augmenter son nombre de téléspectateurs à peu de frais…
La chaîne revendiquait pour juin 2017, 226 000 téléspectateurs par jour et 2.2. Millions par mois.
Ce principe ne va pas amener des millions de téléspectateurs en plus, mais quand même. Nous entendons déjà les arguments qui pourront être avancés: la majorité des foyers n’éteignent pas leur décodeur (pas d’idée sur le sujet), ce ne sont que quelques « nouveaux » téléspectateurs, … d’autres groupes l’ont déjà fait… Si ça ne change rien pourquoi cela a-t-il été fait? De beaux échanges hors et chez Mediametrie à venir!!
Ceci nous ramène des années en arrière quand les postes de télévision s’allumaient, d’office, sur le premier canal, la première chaîne.
En avril 2016, (après 4 ans de discussion) était adopté au niveau européen, le « règlement général sur la protection des données » (RGPD ou GDPR en anglais ). RGPD entrera en application en mai 2018, nous en avons déjà parlé ici.
En janvier 2017, une nouvelle procédure a démarré, intitulée ePrivacy, qui doit harmoniser les législations relative à la confidentialité des « communications électroniques ».
Le monde de la communication est contre ePrivacy, que ce soit les annonceurs, les régies publicitaires, les media y compris internet (sauf Google et Facebook) et, aussi, le monde des études.
Une telle unanimité contre soi, c’est une belle performance.
On trouvera ici une version du 8 septembre de ce texte avec toutes les modifications déjà faites.
Une coalition pour la mesure d’audience (ESOMAR et beaucoup d’autres) a été créée et a publié, le 21 septembre 2017, une déclaration demandant des modifications de l’article 8 le retrait d’un mot et l’ajout d’un autre, et ça change tout!
“If it is necessary for
webaudience measuring, provided that such measurement is carried out by, or on behalf of, the provider of the information society service requested by the end-user”,
Affaire à suivre.
Tel est le résultat d’une étude menée en septembre 2017 par IDCOMMS, une société de conseil aux annonceurs (oh c’est bizarre…) auprès de 229 répondants du monde du marketing, des agences media, de l’achat, 77% des répondants sont Européens, 11% Etats-Uniens et 12% le reste du monde.
En réalité étude, une telle présentation signifie un questionnaire en ligne en anglais sur une base adresse que l’on ne connait pas…
Ces informations publiées le 20 novembre 2017 sont reprises dans bon nombre de media de langue anglaise.
Tout le monde se fiche, comme d’habitude, de la façon dont l’étude est construite, seuls les résultats comptent…Elle est peut-être très bien cette étude mais pourquoi ne pas dire la source des mails des répondants tout simplement. Quant à avoir de la nuance dans l’analyse sur, par exemple, l’expérience des annonceurs en la matière, rien.
Bref, si vous voulez la lire c’est là (en anglais).
On a demandé pendant la seconde guerre mondiale, à un ingénieur anglais, d’améliorer les avions en les blindant. Le blindage étant lourd, il fallait trouver les bons endroits où le mettre sur les avions. Cet ingénieur a alors étudié les impacts sur les avions qui étaient revenus des terrains d’opération. Mais il s’est rendu compte qu’il faisait fausse route, il aurait dû étudier les restes des avions qui n’étaient pas revenus à bon port.
Pour la donnée digitale c’est la même chose !
Le marché confond avoir de la data et avoir de la data de bonne qualité.
Pour Petit Bateau, savoir si une acheteuse est « une mère, une maman, une amie » est important pour déterminer le type d’offres leur proposer. Plutôt que de mettre une usine à gaz en route pour essayer de déterminer leur statut, il est plus simple de leur demander ! Ce sont bien les cas d’usage qui révèlent la valeur de la data et non la data en soi !
Avec des clients, on ne parle pas parler d’Intelligence Artificielle mais de franchir les étapes de base : pourquoi ? Quelles données fiables ? Quelles règles métier ? Quelles mesures… ? l’IA peut servir à automatiser des choses.
Si on ne respecte pas la base, … peinture sur M…. égale M…. (mon résumé !)
Celles des mails, pas le contenu mais les meta données de chaque mail (si vous êtes sur gmail, prenez un de vos mails, cliquez sur la flèche à droite et faites « afficher l’original », vous verrez. Ça doit être du même genre sur Outlook de Microsoft) ainsi que des informations plus classiques comme le titre du salarié, sa localisation, et les réponses à une enquête (satisfaction des employés vs leur manager). Tout ceci aux USA, sur des données de 2015, avec toutes les garanties de préservation de la vie privée de la terre !
Avec des données de mail, peut-on prédire :
Là, ils se sont amusés (moi j’aime !) à procéder à 3 types d’analyse :
Ils ne se sont intéressés qu’au 15% d’individus insatisfaits.
| Questions posées | Modèle logistique | Random Forest SANS les données mail | Random Forest AVEC les données mail | Caractéristique du mail la plus prédictive |
| Satisfaction vs son propre manager | 20% | 69% | 93% | Délai de réponse du manager (le pire, un long délai) |
| Collaboration dans l’entreprise | 27% | 70% | 89% | Taille du mail de réponse du manager (le pire, une réponse courte) |
| Equilibre vie au travail/vie privée | 18% | 42% | 80% | % de mails envoyés en dehors des heures de bureaux (plus il y en a, plus c’est mauvais) |
D’un point de vue analyse de données, le modèle « random forest AVEC données des mails » est supérieur aux autres solutions.
Sur le fond (colonne de droite), a priori rien de renversant, les résultats sont frappés au coin du bon sens et vous vous dites « tout ça pour ça ! ».
En y regardant à 2 fois, on peut aller plus loin. En prenant, par exemple, l’équilibre privée/travail, si le nombre de mails en dehors des heures travaillées est un facteur important, on aurait pu s’attendre à ce que le volume global de mails reçus ou envoyés ou sa distribution selon les jours aient aussi un effet. NON !
En ressources humaines, comme dans bien des domaines, on pourrait piloter plus facilement la satisfaction des employés en utilisant les données qui existent en flux continu. Avec un grand bémol, NE PAS FLIQUER !!
Au fait, l’image c’est le réseau des employés Microsoft en fonction des échanges mails.
L’article originel (en anglais)
https://medium.com/@duncanjwatts/the-organizational-spectroscope-7f9f239a897c
Tel était l’objet du second petit déjeuner, organisé par l’IREP (que nous avions le plaisir d’animer).
Nous avons accueilli, Dominique Cardon, un des plus grands sociologues mondiaux de l’ère du numérique.
Ce billet est le premier de 2 et reprend les propos de Dominique. Le second reprendra les propos de Yannick Carriou, CEO CXP Group.
« Un algorithme (mot arabe, IXème siècle) est une suite d’instructions réglées produisant un résultat. C’est dans le code informatique, mais ce n’est pas tout le code informatique. » Dominique Cardon Medialab Sciences Po.
Les algorithmes de classement de l’information sur le web ne sont qu’une petite partie des algorithmes qui existent mais sont intéressants par ce qu’ils montrent de notre société. Ils peuvent être classés en 4 familles qui sont, aujourd’hui, constamment coprésentes : popularité, autorité, réputation et prédiction.
| A côté | Au-dessus | Dans | Au-dessous | |
| Exemples | Mediametrie // Net Ratings, Google Analytics, affichage publicitaire digital | PageRank de GooglE, Digg, Wikipedia | Nombre d’amis, Facebook, retweet de Twitter, notes et avis | Recommandations Amazon, publicité comportementale |
| Données | Vues | Liens | Likes | Traces |
| Population | Echantillon représentatif | Vote censitaire, communautés | Réseau social, affinitaire, déclaratif | Comportements individuels implicites |
| Forme de calcul | Vote | Classements méritocratiques | Benchmark | Machine learning |
| Principe | POPULARITE | AUTORITE | REPUTATION | PREDICTION |
In Dominique Cardon, A quoi rêvent les algorithmes, la république des idées, Seuil, 2015
Ce qui occupe le monde aujourd’hui, c’est la dernière famille, la prédiction personnalisée. Cette famille est un vrai changement de paradigme, de statistiques, des types de données mobilisées (données publiques, liens hypertexte, partages, like…). Ici, on utilise des données implicites, les traces des internautes, traces de navigation, géolocalisations, … tout ce que peuvent apporter les capteurs aujourd’hui.
« Le rêve de Google a toujours été d’être invisible de l’internaute » Dominique Cardon, Medialab Sciences Po
Cette classification montre que la position du calculateur a, elle aussi, changé: « À côté » , « au-dessus » , « dedans » et « en-dessous »
Le rêve de Google a toujours été d’être invisible de l’internaute (ne pas montrer les calculs) car il prétend mesurer des signaux et faire une prédiction à partir de signaux que les webmestres s’envoient entre eux (liens hypertexte) sans que les webmestres n’agissent en fonction de celui qui les observent du dessus.
Cette vision d’observation du monde (l’instrument qui observe, n’agit pas sur le monde qu’il mesure) est un peu naïve, car les webmestres agissent en fonction de l’instrument qui le mesure. La grande crise du PageRank en 2007-2012 vient de là (Pour compléter votre information voir ici )
A l’opposé, les réseaux sociaux (Facebook, Twitter, …) qui sont DANS la donnée, ont montré les calculs et ont donné à TOUS la possibilité de calculer. Tout le monde peut agir et devenir stratège. La conséquence de ceci a été la forte baisse de qualité de la donnée (achat de faux likes…). Ce qui n’empêche pas les données des réseaux sociaux d’avoir d’autres significations.
Comme la prévision ne fonctionne pas avec le web social (élections, succès commerciaux de films…), pourquoi ne pas aller chercher des traces en dessous, sous la conscience des utilisateurs ?
C’est le grand mouvement actuel dit « l’intelligence artificielle » (l’IA) qui, d’ailleurs, n’est pas de l’IA mais du machine learning. On peut régler les calculs d’une mesure en fonction d’un objectif supervisé qui est toujours une mesure d’utilité (« Qui passe le plus de temps à scroller la page FB » … « que l’on ait de l’up-selling dans la recommandation commerciale », « qui clique le premier », …). L’objectif sert à recalculer les paramètres des données qui vont être présentées de façon de plus en plus personnalisée à l’utilisateur.
C’est un nouveau régime qui se met en route, le calcul n’est plus le même pour tout le monde et le réglage du calcul ne se fait pas en fonction des intentions du calculateur mais en fonction des traces des individus.
Obtenir les réponses à ces questions est une utopie ? Non une réalité, TVision fournit les réponses.
Vous prenez le meilleur de ce qui est appelé la « computer vision science »
![]()
![]()
![]()
![]()
Ces mesures PASSIVES se font via une caméra spécifique TVision sur le(s) poste(s) TV dans des foyers.
Ce qui est diffusé est détecté par le son du programme en fingerprinting (empreinte unique du programme) et comparé à une base de diffusion existante.
Aujourd’hui dans 8 grandes zones (Atlanta, Boston, Chicago, Dallas, Los Angeles, New York, Philadelphie, Seattle), 7 500 individus de foyers volontaires (11 500 en fin d’année 2017). TVision est aussi installé à Tokyo
Leur intimité est préservée car aucune image ou vidéo ne sort de chaque foyer, seulement des 1 et des 0 qui sont traités chez TVision.

La mesure d’audience de la Télévision en France aujourd’hui (et dans de nombreux pays) est « la présence dans la pièce où le poste est allumé ». On enregistre donc une Occasion De Voir (ODV), Occasion To See en anglais (OTS) et non une vision réelle.
Pourquoi alors ne pas compléter l’information à partir de la séquence suivante:
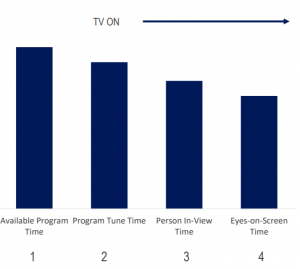
On peut alors calculer :
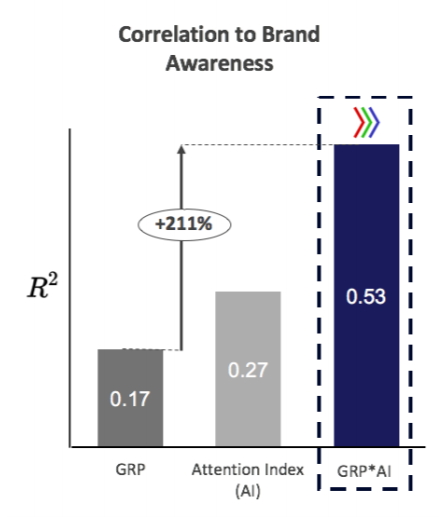
Mc Donald’s au Japon en 2016 a constaté que la corrélation entre ses GRP TV et sa notoriété était de plus en plus faible (0.17). Après analyse des résultats d’attention de TVision et des GRP classiques, Mc Donald’s a fait modifier son media planning et a vu cette corrélation progresser très significativement.
Depuis Mc Donald’s
Quel que soit le coté (Diffuseur ou annonceur), ces indicateurs ne remplacent pas la mesure officielle (Nielsen) aux USA qui fait consensus depuis des années, mais ils les enrichissent dans le sens d’une plus grande efficacité grace à une meilleure compréhension des phénomènes via plus de qualitatif.
Il est intéressant de voir qu’avec la notion de visibilité, la mesure TV se rapprocherait du Web (nous reviendrons sur ce sujet).
Soyons pragmatique, le propos n’est pas de souhaiter le remplacement de la mesure d’audience de la TV (désolée pour le titre de cet article !) pour basculer vers un système de ce type.
Mais, pourquoi ne pas traiter le problème de façon « qualitative » sur un petit échantillon, voire une zone test, de façon à fournir les moyens,
Alors, les sociétés d’études qui s’y met ? Mediametrie ? Kantar ? Ipsos ? GfK ? Marketing Scan ? Iligo ? …
Nous connaissons la réponse de nombre d’entre elles : « Qui finance ? » Et? c’est comme cela que la France est devenue un petit pays dans le domaine des études (notre avis). Beaucoup de choses se passent aux USA, en Grande Bretagne, voire en Australie (pour ceux qui n’ont pas encore lu le billet sur la mesure d’attention en Australie, cliquez ici), là où il y a encore un peu d’argent pour avoir des vraies réponses à de vraies questions et faire gagner beaucoup d’argent aux annonceurs.
Merci à TVision pour les informations et les images fournies.
Pour ceux qui s’intéressent à l’attention, voir ici là et ici.
© 2024 tracksandfacts tracks&facts tracks & facts
Theme by Anders Noren — Up ↑






{kind=link}
, le parcours du consommateur ON et OFF (Carrefour Media) (compte rendu impartial et complet)){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
){kind=link}
){kind=link}